

1. 서 론
2. 정면충돌 시험 결과 및 평균가속도
3. 딥러닝 모델 구성 및 평가
3.1. DNN 모델의 구성
3.2. DNN 모델 구성을 위한 가정 및 조건 설정
3.3. DNN 모델 구성을 위한 사례연구 1
3.4. DNN 모델 구성을 위한 사례연구 2
4. 결 론
1. 서 론
충돌 가속도 곡선(Crash pulse)을 이용하여 HIC15 및 흉부변형량(Chest deflection) 등과 같은 인체상해치를 예측하고자 하는 연구들이 발표되어 왔다.(1~4) 이는 실차충돌시험이나 실차의 유한요소해석을 통하지 않고도, 기존의 충돌시험 데이터베이스를 활용하여 신차개발 단계 등에서 인체상해치를 예측하기 위한 수학적인 모델을 구성하기 위한 것이다.(1~4)
충돌 가속도 곡선을 10 ms 구간으로 구분한 후에 각 구간에서 평균가속도 값을 이용한 선형회귀모델은 비교적 높은 정확도를 가지고 HIC15를 예측할 수 있음을 알 수 있다.(2~4) 흉부변형량 선형회귀모델의 경우에는 HIC15 예측모델에 비해 다소 정확도가 떨어지는 것도 알 수 있었다.(2,3) 흉부변형량 예측모델의 정확도가 HIC15 예측모델에 비해 떨어지는 원인은, 가속도 값과 변형량 사이에 적절한 연관관계를 만들기 위한 적합한 인자를 찾아내지 못한 것에 기인한 것으로 보인다.
최근 머신러닝을 이용하여 해결책을 찾으려는 연구들이 다양하게 진행되고 있다. 자율주행과 관련된 분야에서, 특히, 알고리즘 개발 등에 활발하게 적용되고 있다.(5,6) 딥러닝은 신경망을 기반으로 학습하는 방법이며, 이미지나 음성인식과 같은 복잡한 문제를 해결하는데 적합하다고 알려져 있다.(7,8)
본 연구에서는 딥러닝을 적용하여 정면충돌 시 흉부변형량을 예측하는 모델을 개발하고자 한다. 충돌 가속도 곡선으로부터 구한 10 ms 구간별 평균가속도 값 및 공차중량(CVW: Curb Vehicle Weight)을 기반으로 하여 하이퍼 파라미터(Hyperparameter)를 변화시키면서 심층 신경망(DNN, Deep Neural Network)을 구성하고 이들로부터 적합한 모델을 구하고자 하였다. 충돌 가속도 곡선은 MY2018~MY2020에 실시된 USNCAP 정면충돌시험 데이터베이스에서 구한 110개 차종의 시험 결과를 이용하였다.(9)
2. 정면충돌 시험 결과 및 평균가속도
정면충돌시험 결과는 NHTSA의 USNCAP 데이터베이스에서 MY2018 30차종, MY2019 45차종 및 MY2020 35차종 등 총 110개 차종으로부터 구하였다.(9) 시험차종은 승용차, SUV 및 픽업트럭 등으로 다양하게 구성되어 있다. 시험차종이 110개이므로, 차종별 및 각 구간별 평균가속도 데이터와 공차중량, 운전자 및 탑승자 흉부변형량의 일부를 Table 1에 나타내었다.
자동차의 충돌 가속도 곡선으로부터 구하는 10 ms 구간별 평균 가속도는 충돌시험에서 구해진 원데이터(Raw data)를 가공하여 만든다. 먼저 B 필라(Pillar) 하단부 좌우에서 측정된 두 가속도의 평균값을 구하고 60 Hz로 필터링하여 노이즈를 없앤다. NHTSA의 충돌시험 데이터는 대체로 0.1 ms 또는 그 이하 시간 간격으로 샘플링되어 있기 때문에, 데이터 개수를 줄이기 위하여 1 ms 시간 간격으로 다시 샘플링한다. 필터링(Filtering)된 가속도 값을 적분하여 속도를 구한 후에, 100 ms까지 각각 10 ms의 10개 구간에서 평균가속도 값을 구한다.(2~4) 10 ms 구간의 평균가속도 값은 Table 1에 나타낸 것과 같이 구해진다.
3. 딥러닝 모델 구성 및 평가
3.1. DNN 모델의 구성
딥러닝 모델은 은닉층(Hidden layer)이 2개 이상으로 구성되며, 입력층(Input layer), 은닉층, 출력층(Output layer)으로 구분되는 기본적인 구성도는 Fig. 1과 같다. DNN 모델의 성능을 결정하는 요소들은 훈련데이터의 수 ntr, 입력층의 뉴런 수 n, 출력층의 뉴런 수 m, 은닉층의 수 Nh, 은닉층의 뉴런 수 Nn, 활성화 함수의 종류, 배치(Batch)의 수 Nb, 에포크의 수, 최적화 알고리즘의 종류 및 학습률 등 다양하다.(7,8) 본 연구에서는 주어진 0~100 ms까지의 10 ms 구간별 10개의 가속도 데이터를 기본 입력 뉴런으로 선정하고 입력 뉴런에 공차중량의 포함 여부에 따른 각각의 DNN 모델을 구성한다. 그리고 운전자 및 탑승자의 흉부변형량을 독립적인 출력층으로 설정하여 DNN을 구성하므로 Fig. 1에서 m=1이다.
운전자 또는 탑승자의 흉부변형량은 종속변수이며, 10개의 평균가속도 데이터와 공차중량은 독립변수로 간주되어 종속변수와 독립변수의 함수관계를 DNN 모델로 구성하는 것이다.
3.2. DNN 모델 구성을 위한 가정 및 조건 설정
MY2018부터 MY2020까지의 USNCAP 정면충돌 시험 결과 중 110개를 갖고 본 연구를 수행하였다. 이 중에서 80개는 훈련데이터(ntr)로 30개는 테스트데이터(nte)로 사용한다. 80개의 데이터 중에서 10%인 8개 또는 20%인 16개는 검증(Validation)을 위한 데이터로 사용된다.
본 연구에서의 DNN 모델은 구글 텐서플로우(Tensorflow)를 이용하여 구글 코랩(Colab) 상에서 구성되었다.(10) 활성화 함수로는 LeakyReLU를, 스케일러로는 MinMaxScaler 클래스를, 최적화 알고리즘으로는 Adam을 각각 이용하였다.(8,10,11) 다음 절의 사례연구 1에서는 비교적 작은 2개의 은닉층 수와 은닉층의 뉴런 수를 갖고 운전자와 탑승자의 흉부변형량을 예측하였다. 더불어 공차중량 여부에 따른 흉부변형량의 예측치를 비교하였다. 반면에 사례연구 2에서는 5개의 은닉층과 큰 은닉층의 뉴런 수를 갖고 운전자와 탑승자의 흉부변형량을 예측하였다. 두 가지의 사례연구에서 모두 가중치의 초기값에 대하여 다른 모델이 생성되므로 10회의 실행을 함으로써 DNN에서 회귀모델의 경우 모델 성능을 판단하는 지수로서 다음의 MSE(Mean Squared Error)와 MAE(Mean Absolute Error)의 최상의 값 및 평균과 표준편차를 산출하였다.(11)
여기서 δi는 i 번째 테스트데이터의 흉부변형량, 는 흉부변형량의 예측값이다.
3.3. DNN 모델 구성을 위한 사례연구 1
운전자와 탑승자의 흉부변형량 예측을 위하여 각각에 대하여 공차중량을 제외한 10개의 평균가속도를 입력 뉴런으로 하는 DNN 모델과 공차중량과 10개의 평균가속도, 즉 11개의 입력 뉴런으로 하는 DNN 모델을 구성하였다. Table 2와 3은 운전자 및 탑승자에 대하여 공차중량을 포함함으로써 n=11로 하고, 은닉층의 수, Nh=2, 학습률, a=0.0001로 고정하고, 입력뉴런의 개수 n에 대하여 은닉층의 뉴런 개수를 4n, 5n, 6n으로 변화시키면서 배치수 Nb를 10, 20으로, 검증데이터비율 Ns를 0.1, 0.2로 한 조합에 대하여 12개의 DNN 모델의 MSE와 MAE를 구한 것이다.(11) 모든 케이스에서 에포크 수는 5,000이다. 운전자와 탑승자에 대하여 텐서플로우를 통해 구해진 DNN 모델의 성능을 Table 2와 Table 3에 각각 정리하였다.
Table 2.
Performance of DNN for chest deflection on driver side with CVW considered (Case study 1: Nh=2, a=0.0001)
Table 3.
Performance of DNN for chest deflection on passenger side with CVW considered (Case study 1: Nh=2, a=0.0001)
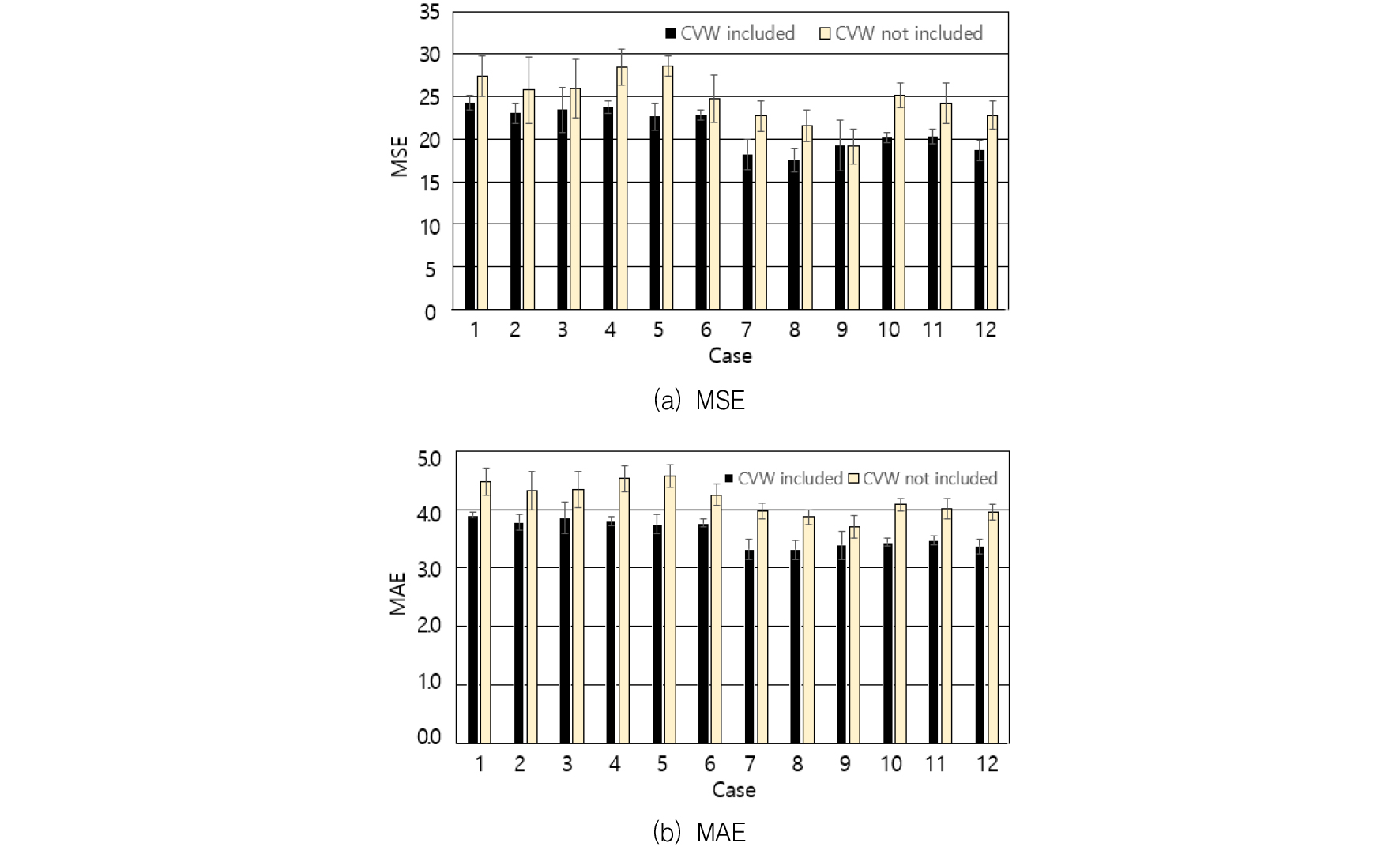
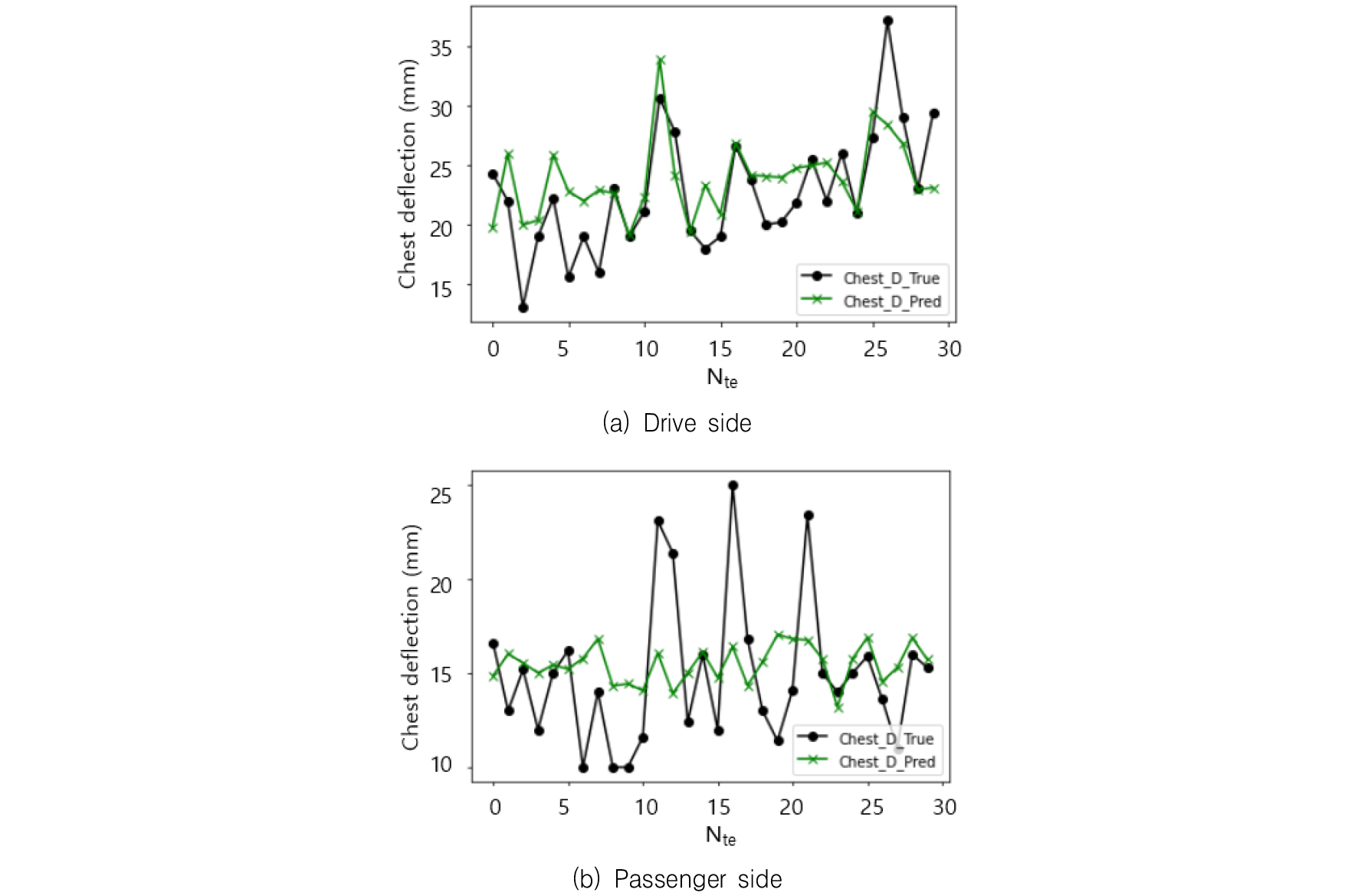
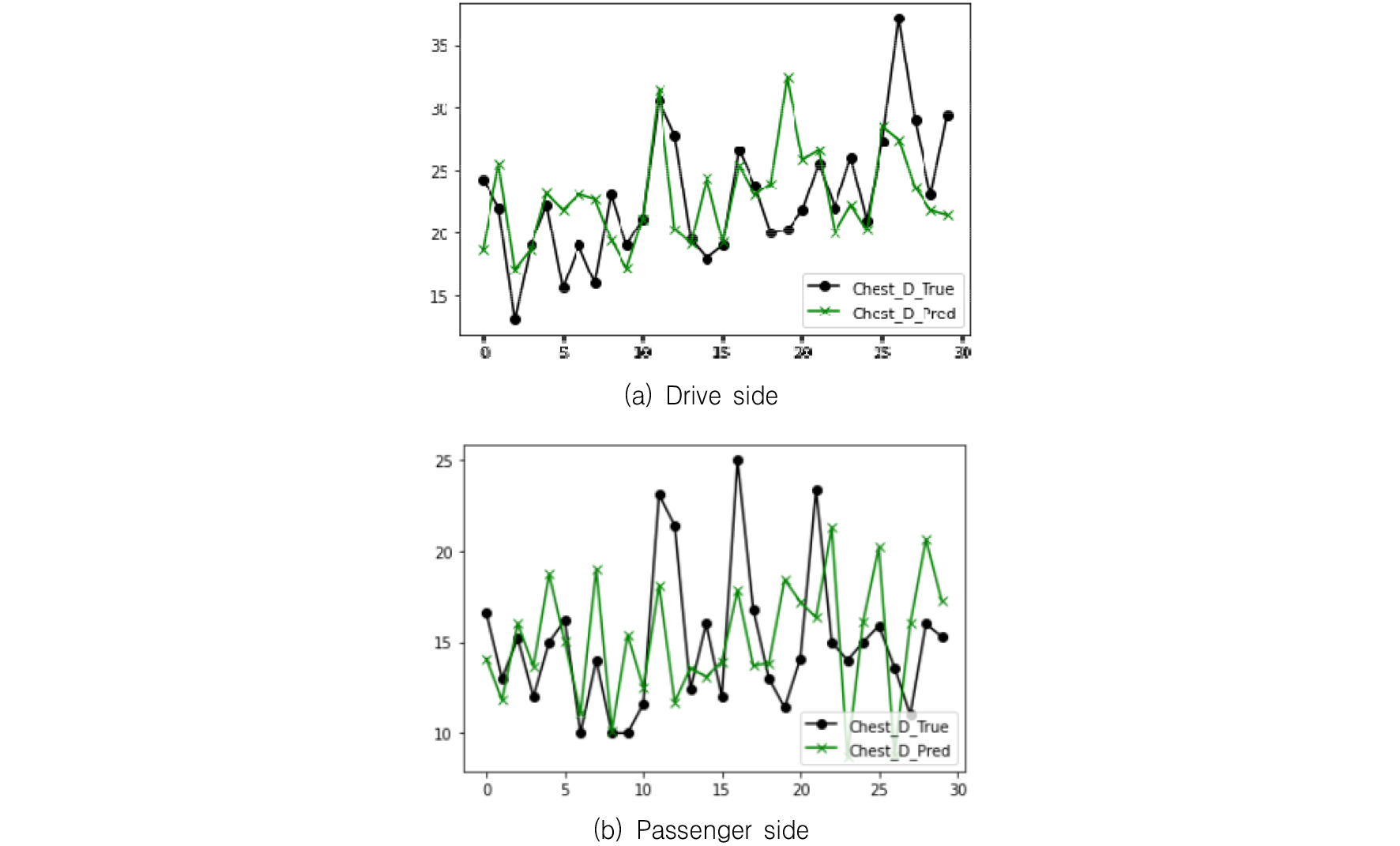
텐서플로우에서는 가중치의 초기치에 따라 다른 DNN 모델이 구해질 수 있으므로,(10) 12가지 경우 각각에 대하여 10회의 모델을 반복적으로 구해 테스트데이터에서의 10개의 MSE와 MAE를 구하였다.(11) 이로부터 가장 작은 값을 갖는 MSE와 MAE는 Table 2와 Table 3에서 MSE*와 MAE*로 표시하였으며 각각의 평균 및 표준편차는 첨자 m과 s로 표시하였다. Table 4와 Table 5는 입력뉴런으로 10개의 평균가속도만을 고려하여 n=10으로 설정하고, 그 이외의 조건은 n=11인 경우와 동일하게 했을 때의 DNN 모델의 성능을 정리한 것이다. 공차중량을 포함한 모델에서는 가장 좋은 지수들은 운전자에서 MSE*는 14.799, MAE*는 3.013, 탑승자에서 MSE*는 13.702, MAE*는 2.932가 산출되었으며 공차중량을 제외한 모델에서는 운전자에서 MSE*는 16.568, MAE*는 3.533, 탑승자에서 MSE*는 14.530, MAE*는 2.980이 산출되었다. 운전자 및 탑승자에 대하여 공차중량을 입력뉴런으로 반영했을 경우와 그렇지 않은 경우에 대하여 MSE와 MAE의 평균 및 표준편차를 Fig. 2 및 Fig. 3에 각각 표시하였다. 운전자 및 탑승자에서 모두 MSE와 MAE의 평균 및 표준편차가 공차중량을 입력뉴런으로 고려한 경우가 그렇지 않은 경우에 비하여 상대적으로 작게 나타나고 있음을 알 수 있다. 30개의 테스트데이터에 대한 참값과, 운전자는 Table 2에서 case 8, 탑승자는 Table 3에서 case 5에 대한 DNN 모델의 예측값을 Fig. 4에서 비교하였다. 운전자의 MSE, MAE가 탑승자의 것보다 미소하게 크게 나타나고 있지만 전체적인 경향성은 탑승자의 모델에 비교하여 보다 적합하게 나타났다. 테스트데이터 11-21번 사이에서 탑승자의 흉부변형량 예측값이 참값과 매우 큰 차이를 보이고 있다.
Table 4.
Performance of DNN for chest deflection on driver side without CVW considered (Case study 1: Nh=2, a=0.0001)
Table 5.
Performance of DNN for chest deflection on passenger side without CVW considered (Case study 1: Nh=2, a=0.0001)
3.4. DNN 모델 구성을 위한 사례연구 2
사례연구 2에서는 사례연구 1에서 설정한 은닉층의 수와 은닉층의 뉴런 수를 증가시켜 공차중량이 포함된 DNN 모델의 성능을 평가하였다. 입력 뉴런은 공차중량과 10개의 평균가속도의 11개로 구성되며 은닉층의 수 Ns=5, 학습률 a=0.00001로 고정하였고, 입력뉴런의 개수 n에 대하여 은닉층의 뉴런 개수를 50n, 75n, 100n으로 변화시키면서 배치수 Nb를 10, 20으로, 검증데이터비율 Ns를 0.1, 0.2로 한 조합에 대하여 12개의 DNN 모델의 MSE와 MAE를 구한 것이다. 모든 경우에 에포크 수는 5,000이다. 운전자와 탑승자에 대하여 텐서플로우를 통해 구해진 DNN 모델의 성능을 Table 6과 Table 7에 각각 정리하였다.
Table 6.
Performance of DNN for chest deflection on driver side with CVW considered (Case study 2: Nh=5, a=0.00001)
Table 7.
Performance of DNN for chest deflection on passenger side with CVW considered (Case study 2: Nh=5, a=0.00001)
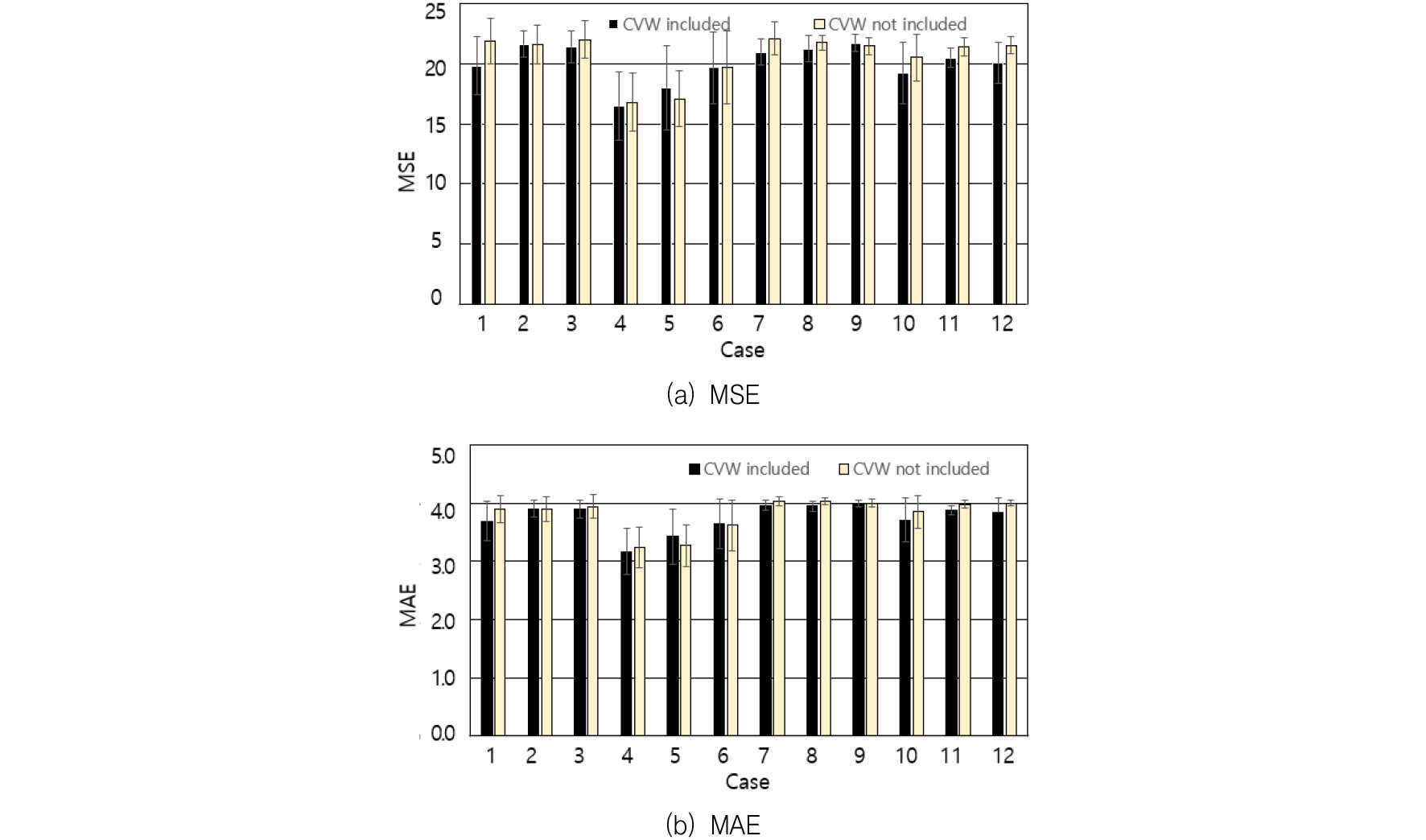
운전자의 MSE*는 20.709, MAE*는 3.489, 탑승자의 MSE*는 18.204, MAE*는 3.471이 산출되었다. 이들은 사례연구 1보다 큰 값들이다. 30 개의 테스트데이터에 대한 참값과, 운전자는 Table 6에서 case 3에 대한, 탑승자는 Table 7에서 case 1에 대한, DNN 모델의 예측값의 비교를 Fig. 5에 정리하였다. 운전자의 경우 Fig. 5(a)의 DNN 모델은 Fig. 4(a)의 DNN 모델과 큰 차이를 보이고 있지 않지만 탑승자의 경우 Fig. 5(b)의 DNN 모델은 Fig. 4(b)의 DNN 모델에 비해 보다 일관성 있는 모델로 판단된다.
4. 결 론
본 연구에서는 MY2018~MY2020년에 걸쳐 시행된 USNCAP 정면충돌시험의 가속도 데이터를 기초로, 이를 평균화하여 100 ms까지 10개의 평균가속도 데이터로 변환하고, 이를 입력뉴런으로 하는 DNN 모델을 구글 텐서플로우를 이용하여 생성하였다. DNN 모델은 운전자와 탑승자에 대해 각각 생성되었다. 또한 10개의 평균가속도 데이터에 공차중량을 포함시켜 11개의 입력뉴런으로 하는 DNN 모델을 생성하여 테스트데이터를 갖고 DNN 모델을 평가하였다. 평가 결과 공차중량을 포함하는 모델들은 그렇지 않은 모델에 비하여 RMSE, MAE 모두 작은 값들을 보이고 있어, 공차중량을 포함한 DNN모델이 보다 신뢰성 있는 모델로 판단된다. 은닉층의 수 Nh=2인 경우, 공차중량이 포함된 모델에서는 운전자의 흉부변형량에 대한 MSE*=14.799, MAE*=3.013인 반면, 탑승자의 MSE*=14.053, MAE*=2.932로서 탑승자에 대한 예측 평가가 약간 우수한 결과를 보이고 있다. 공차중량이 포함되지 않은 모델에서도 운전자의 MSE*=16.568, MAE*=3.533인 반면, 탑승자의 MSE*=14.530, MAE*=2.980로서 탑승자에 대한 예측 평가가 더욱 우수한 결과를 보이고 있다. 은닉층의 수 Nh=5인 경우도 일관된 결과를 보이고 있다. 비록 그 차이가 크지 않지만 이러한 경향은 좌우측 가속도에 대한 평균이 탑승자에 대하여 보다 민감하게 작용한다고 판단된다.
본 연구에서는 딥러닝을 구성하는 하이퍼파라미터 중 은닉층의 수, 은닉층의 뉴런 수, 배치 수 등을 변화시키면서 각 모델을 평가하였다. 은닉층의 변화에 대하여, 운전자의 Nh=2인 결과인 Fig. 4(a)와 Nh=5인 결과인 Fig. 5(a)를 비교하면 경향은 비슷한 것을 알 수 있다. 반면에 탑승자의 Nh=2의 결과인 Fig. 4(b)와 Nh=5의 결과인 Fig. 5(b)를 비교하면 Fig. 5(b)가 실제값의 변동을 잘 설명해 주고 있다. 그러나 MSE*와 MAE*의 값을 비교하면 은닉층의 수, 뉴런의 수, 배치 수, 검증데이터 비율의 효과가 서로 교락되어 있어 각각의 증감에 따른 신뢰도를 평가하기는 어렵다. 딥러닝 모델의 불확실성은 크게 앨리오토릭 불확실성(Aleatoric uncertainty)와 에피스테믹 불확실성(Epistemic uncertainty)로 분류할 수 있다.(12) 전자는 데이터 자체가 가지고 있는 고유한 잡음으로 발생하는 것이며 후자는 모델이 데이터를 제대로 설명하지 못하는 불확실성이다. 에피스테믹 불확실성은 데이터 수를 증가시키면 극복할 수 있으나 전자에 의한 불확실성은 줄일 수 없다. 본 예제는 두 가지의 불확실성을 모두 포함하고 있다.
본 연구는 매우 한정된 110개의 데이터를 갖고 모델을 구성했기 때문에, 이로부터 발생하는 근사모델의 에피스테믹 불확실성은 데이터를 증가시키면 감소시킬 수 있다. 각 사례연구에서 평가지수인 MSE와 MAE의 최상값, 평균, 표준편차, 그리고 테스트데이터의 참값과 예측값의 비교 그래프를 보면 운전자 및 탑승자와 평균가속도 및 공차중량의 함수관계를 파악할 수 있었다. 보다 확충된 데이터를 갖고 흉부변형량의 DNN 모델을 구성하는 것과 베이지안 딥러닝(Bayesian deep learning)을 도입하여 불확실성을 예측하는 것을 향후 연구과제로 남겨둔다. 또한 머리상해치(HIC)에 대해서도 관련 연구를 확장하는 것이 필요하며 최적의 흉부변형량 산출을 위한 평균가속도값을 예측하는 연구가 요구된다.
