

1. Introduction
2. Vehicle Modeling
2.1. Definition of Slip Angles
2.2. Vertical Load Model
2.3. Fiala Lateral Force Model
2.4. Steering Model
2.5. Definition of Lateral Acceleration and Yaw Rate
2.6. Substep Based Integration
3. Reinforcement Learning Environment
3.1. Reinforcement Learning Framework
4. Scenario Design and Results
4.1. Scenario Design
4.2. Results
5. Conclusion
1. Introduction
Path tracking, a core function of autonomous vehicles, involves controlling steering to precisely follow a designated path. Especially during high-speed maneuvers or on paths with high curvature, steering inputs lead to significant changes in vehicle attitude. Furthermore, uncertainties exist as vehicle responses vary depending on driving speeds, even under identical control inputs. In environments characterized by such nonlinearities and uncertainties, it is challenging to ensure consistent performance and stability across all driving conditions using only linearization-based models or fixed-gain control methods. Therefore, this study employs reinforcement learning algorithms, which can learn control policies through interactions across diverse conditions and operate stably even in the presence of model uncertainties.
To account for nonlinear tire dynamics, this study constructs a vehicle dynamics model based on the Fiala tire model,(1) which utilizes a relatively small number of parameters. Additionally, to enhance yaw rate tracking performance, a steering architecture incorporating both front-wheel and rear-wheel steering is applied. This configuration aims to reduce errors relative to the target yaw rate and ensure more stable path tracking performance. Furthermore, the front-and-rear steering structure adopted in this study is designed with future extensibility to E-Corner vehicle platforms—which include four-wheel independent steering(2) and driving—in mind. This provides a foundation for RL policies to integrally learn the interactions between control inputs even in environments with the expanded degrees of freedom provided by corner modules.
In this study, the Soft Actor-Critic(3) algorithm, an off-policy method, is applied to train the yaw rate tracking policy, ensuring stable learning and high sample efficiency in continuous control problems. SAC promotes exploration and enhances convergence stability during the training process through an entropy-regularized objective function that simultaneously maximizes expected rewards and policy entropy. This induces a robust policy capable of handling uncertain environments and dynamic variations. Consequently, this study aims to design a robust path tracking controller that minimizes yaw rate tracking errors and maintains stability under various driving conditions.
2. Vehicle Modeling
In this study, the vehicle dynamics model employs a vehicle mass of 1500 kg, a yaw moment of inertia of 2250 , and distances from the center of gravity to the front and rear axles of 1.2 m and 1.6 m, respectively. The tire cornering stiffness is set to 80,000 N/rad, and the road friction coefficient is assumed to be 0.8.
2.1. Definition of Slip Angles
In this study, a bicycle model is assumed, where the front and rear wheels of the vehicle are modeled as a single equivalent tire each. The front and rear slip angles are defined using the vehicle's lateral velocity , yaw rate , longitudinal velocity , and the respective steering angles and . The front slip angle is defined as in Eq. (1), and the rear slip angle is defined as in Eq. (2).
2.2. Vertical Load Model
The vertical loads acting on the front and rear wheels are defined using a static distribution model that neglects dynamic load transfer. The vertical load for the front wheels is expressed in Eq. (3), and for the rear wheels in Eq. (4).
2.3. Fiala Lateral Force Model
In this study, a brush-based(4) Fiala tire model was employed to incorporate the nonlinear lateral force characteristics occurring at the tire-road contact patch into the vehicle model. This model has the advantage of representing the nonlinear variations in lateral force as the slip angle increases, as well as the saturation behavior caused by friction limits, in a relatively concise form. Furthermore, it enables modeling with a smaller number of parameters(5) compared to other complex tire models. Through this approach, we aimed to ensure both computational efficiency and physical validity required for training the reinforcement learning-based controller.
The lateral forces of the front and rear tires were calculated using the Fiala model, taking each tire's slip angle and vertical load as inputs. When the slip angle is below a critical threshold , the lateral force is expressed as shown in Eq. (5).
The critical slip angle is defined as shown in Eq. (6)
When the slip angle exceeds the critical threshold, the tire lateral force saturates at the friction limit.
2.4. Steering Model
In this study, a second-order steering dynamics model was employed, where the steering input is defined as the steering angular acceleration . This input is integrated to update the steering angular velocity and the steering angle , as expressed in Eq. (7) and Eq. (8), respectively.
2.5. Definition of Lateral Acceleration and Yaw Rate
The vehicle's lateral acceleration and yaw acceleration are defined as shown in Eq. (9) and Eq. (10), respectively.
The state updates for the lateral velocity and yaw rate are expressed in Eq. (11) and Eq. (12), as follows
2.6. Substep Based Integration
To mitigate numerical instability that may occur when performing a single integration over a large time interval, this study conducted numerical integration by dividing each environment step into five sub-steps.
The sub-step-based numerical integration allows for the stable application of steering angle and steering angular velocity constraints over more granular time intervals. Furthermore, it provides a more continuous and stable simulation of the process through which nonlinear tire lateral forces are transmitted to the yaw rate and lateral acceleration responses.
3. Reinforcement Learning Environment
3.1. Reinforcement Learning Framework
3.1.1. Soft Actor-Critic
Soft Actor-Critic is an off-policy actor-critic reinforcement learning algorithm suitable for continuous control problems. In this framework, the actor outputs a stochastic action for a given state , while the critic learns by approximating the action-value function . The core of SAC lies in its entropy-regularized objective function, which promotes exploration(6) and enhances learning stability(7) by maximizing not only the expected cumulative reward but also the entropy of the policy. The entropy-regularized objective function of SAC is defined as shown in Eq. (13).
In Eq. (13), denotes the entropy of the policy, and serves as a temperature parameter that adjusts the weighting of the entropy term, thereby balancing the trade-off between exploration and exploitation. Furthermore, SAC enhances sample efficiency by reusing past experiences through a replay buffer.(8) It also ensures learning stability by employing clipped double-Q learning to mitigate the overestimation of Q-values.(9)
The objective of this study is to train a steering policy capable of ensuring stable path tracking performance even in environments characterized by nonlinear tire dynamics,(10) as described by the Fiala tire model. In such environments, responses to state-action changes can vary sensitively due to the nonlinearity of tire lateral forces. This poses a risk where the policy might prematurely converge to a suboptimal solution or the learning process could become unstable without sufficient exploration.
Reinforcement learning-based control offers the advantage of directly learning the relationships between states, actions, and rewards for these nonlinear systems without the need for explicit model linearization or complex control rule design. While traditional rule-based controller design becomes increasingly difficult as interactions between control inputs grow more complex—particularly in multi-degree-of-freedom control problems—RL enables integral policy learning even within high-dimensional state and action spaces.
Consequently, this study applies the SAC algorithm, which maintains exploration through entropy regularization while performing stable training based on off-policy learning and the double-Q structure. By maintaining the stochastic nature of the policy, SAC secures the ability to explore various driving conditions while simultaneously improving learning stability and data efficiency.
Moreover, the front-and-rear steering configuration considered in this study is intended for future extensibility to E-Corner vehicle platforms, which feature four-wheel independent steering and driving. In such E-Corner-based vehicles, the action space expands significantly due to independent control over each wheel, and the coupling effects between control inputs become highly complex. RL-based control is a particularly suitable approach for vehicle platforms with expanded degrees of freedom, as it can integrally learn these interactions within the policy, even in large action spaces. Thus, this study aims to train a robust yaw rate and path tracking control policy that accounts for both nonlinear tire dynamics and the potential for future expansion to E-Corner platforms through SAC-based reinforcement learning.
3.1.2. Configuration of the Reinforcement Learning Environment
In this study, the SAC algorithm is employed to train a steering policy for yaw rate tracking. The states, actions, and rewards of the reinforcement learning framework are configured to ensure optimal path tracking performance. The specific observations and actions used in the training process are summarized in Table 1.
Table 1.
Components of SAC learning
First, the lateral velocity and yaw rate were included in the observations as they directly influence yaw rate tracking performance and vehicle stability. Next, the steering angles and steering angular velocities of the front and rear wheels were incorporated. These are essential internal states since the system follows a second-order steering dynamics model where the input is defined as steering angular acceleration; including them allows the policy to consider actual steering responses and the proximity to steering constraints.
The target yaw rate provides the reference to be followed at the current time step, while the tracking error serves as direct error feedback representing the control objective, contributing to both learning convergence and tracking precision. Finally, the longitudinal velocity was included to allow the policy to calculate appropriate steering inputs adapted to varying speed conditions.
The final output of the reinforcement learning agent is defined as the steering angular accelerations for the front and rear wheels. By directly controlling the rate of change of the steering input, the policy learns to mitigate discontinuous vehicle responses caused by abrupt steering maneuvers and achieves smooth steering control within the defined constraint boundaries.
3.1.3. Reward Function Design
In this study, the reward function was designed as a weighted sum of a tracking term and a stability term to simultaneously account for yaw rate tracking performance and lateral stability. First, the tracking error term is formulated as shown in Eq. (14).
The reward associated with the magnitude of the lateral velocity , which is related to lateral stability, is structured as in Eq. (15).
The final reward is composed as a weighted sum of these two terms, as shown in Eq. (16), prioritizing tracking performance while also reflecting stability.
Furthermore, to normalize the reward range for more effective learning, a linear transformation was applied to define the final step reward as in Eq. (17).
Based on the previously described sub-step integration, the reward for a single environment step is determined by averaging the rewards calculated at each sub-step, as expressed in Eq. (18).
Finally, regarding the termination conditions, an episode is terminated and a large negative reward is assigned if the lateral velocity increases excessively or the yaw rate tracking error exceeds a certain threshold, signifying a failure state. This approach prevents the policy from entering unstable lateral states or divergent tracking conditions, guiding the learning process toward achieving stable yaw rate tracking.
3.1.4. Training Parameters
The SAC training parameters used in this study are summarized in Table 2.
Table 2.
SAC training parameters
| Parameter | Value |
| Optimizer | Adam |
| Learning rate | 3·10-4 |
| Discount factor | 0.95 |
| Replay buffer size | 106 |
| Number of hidden layers | 2 |
| Number of hidden nodes | 256 |
| Activation function | ReLU |
| Batch size | 256 |
3.1.5. Normalization
In this study, the observations were normalized to enhance the stability and convergence speed of the reinforcement learning process. Since the scales of the physical quantities in the observations vary significantly, gradient scale imbalances can occur during neural network training. To prevent this, all observation values were divided by predefined scale constants before being input into the network. The normalization scale constants used are summarized in Table 3 below.
Table 3.
Normalization statistics of observations
3.1.6. Training Conditions
In this study, to train the reinforcement learning-based yaw rate tracking policy, a training environment was configured where the driving conditions and target yaw rate inputs are randomized for each episode. This approach ensures that the agent encounters a wide range of scenarios, thereby improving the robustness and generalization of the learned policy across diverse operational conditions.
At the start of each episode, a target yaw rate input scenario is randomly selected as either a sinusoidal or a ramp function. The parameters of the selected profile are randomly sampled from the ranges specified in Table 4 and Table 5. The selected scenario remains fixed throughout the duration of that specific episode. This configuration induces the policy to learn robust tracking performance across various types of target yaw rate trajectories.
4. Scenario Design and Results
4.1. Scenario Design
In this study, to ensure the stable performance of the agent, the policy was trained to track a sine-wave target yaw rate under various training conditions. The evaluation scenarios for yaw rate tracking were designed by categorizing the sine-wave target yaw rate tracking, as detailed in Table 6, into two distinct speed conditions.
Table 6.
Yaw rate tracking scenario conditions
| Case 1: Yaw rate tracking | ||
| Velocity [m/s] | 10 | 20 |
| Frequency [Hz] | 0.2 | |
| Amplitude [rad/s] | 0.1 | |
To quantitatively verify the agent's performance, including stability during the yaw rate tracking process, we selected the target yaw rate tracking error, front and rear steering angles, and lateral velocity as the primary evaluation metrics.
In addition, to evaluate the generalization performance of the policy trained on sine-wave and ramp-type target yaw rates, a path was constructed as shown in Fig. 1 using road data acquired from the KIAPI Proving Ground. The evaluation scenario was conducted under a constant speed condition of 20 m/s, as detailed in Table 7.
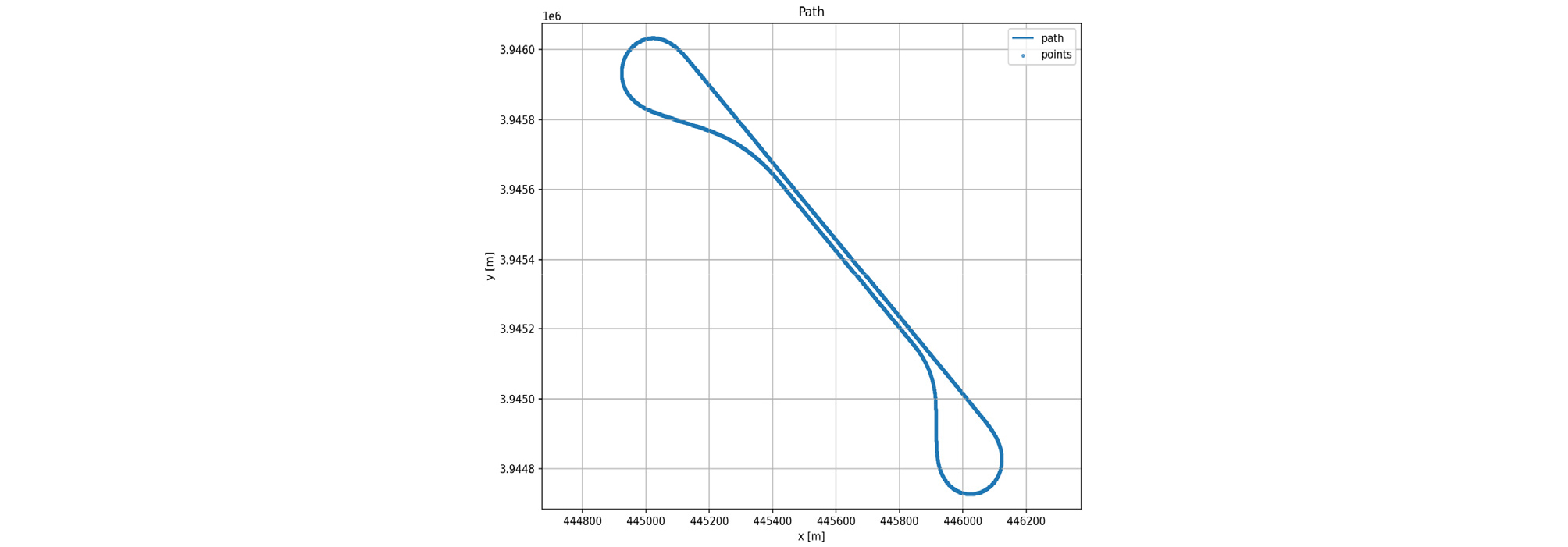
The target curvature was calculated by applying the Pure Pursuit algorithm to the x and y coordinates of the centerline extracted from the road data. Subsequently, the target yaw rate was generated by combining this curvature with the vehicle's longitudinal velocity.
4.2. Results
4.2.1. Case 1: Target Yaw Rate Tracking
The simulation results for the constant speed conditions of 10 m/s and 20 m/s are presented in Fig. 2 and Fig. 3, respectively.
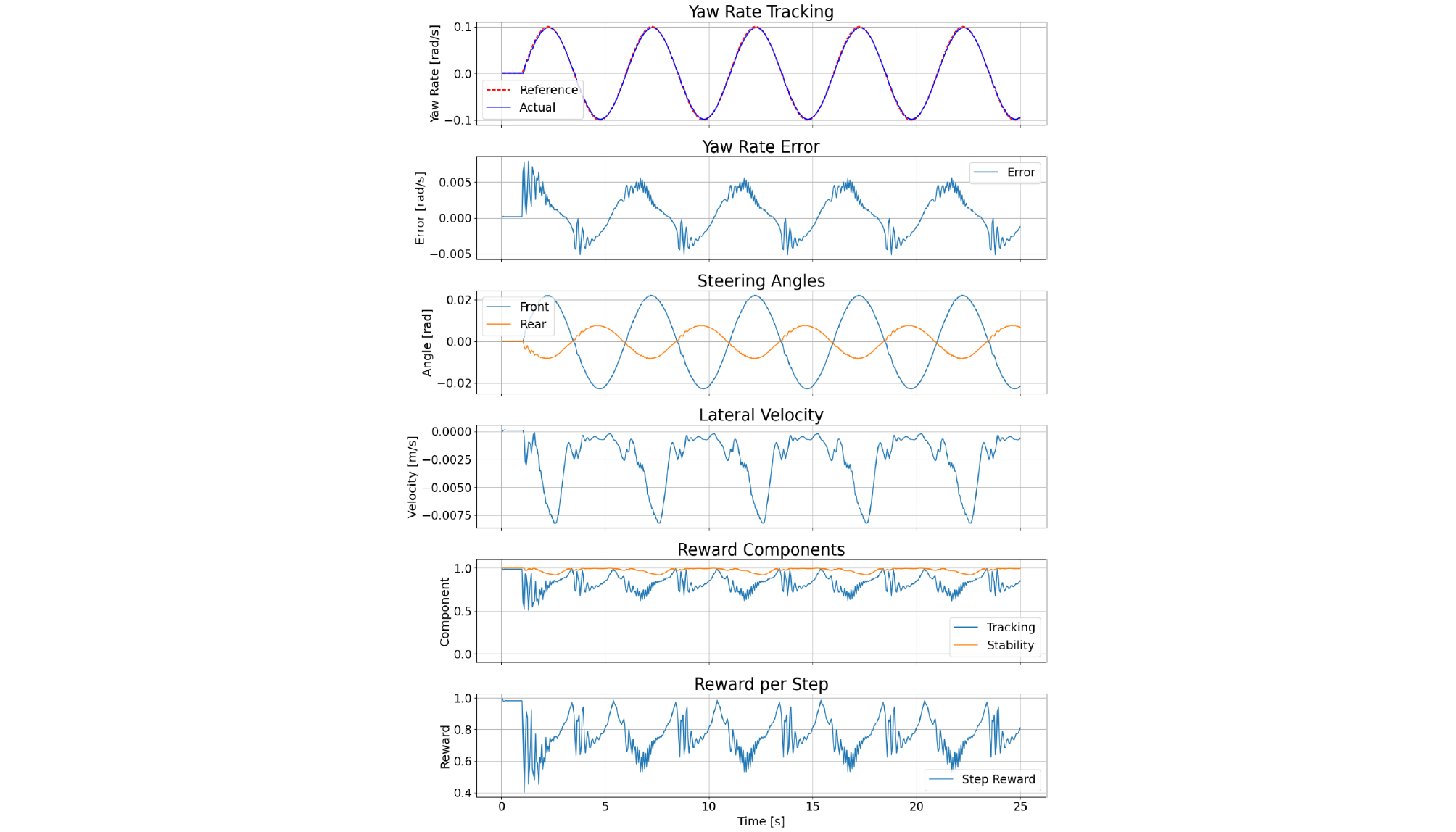
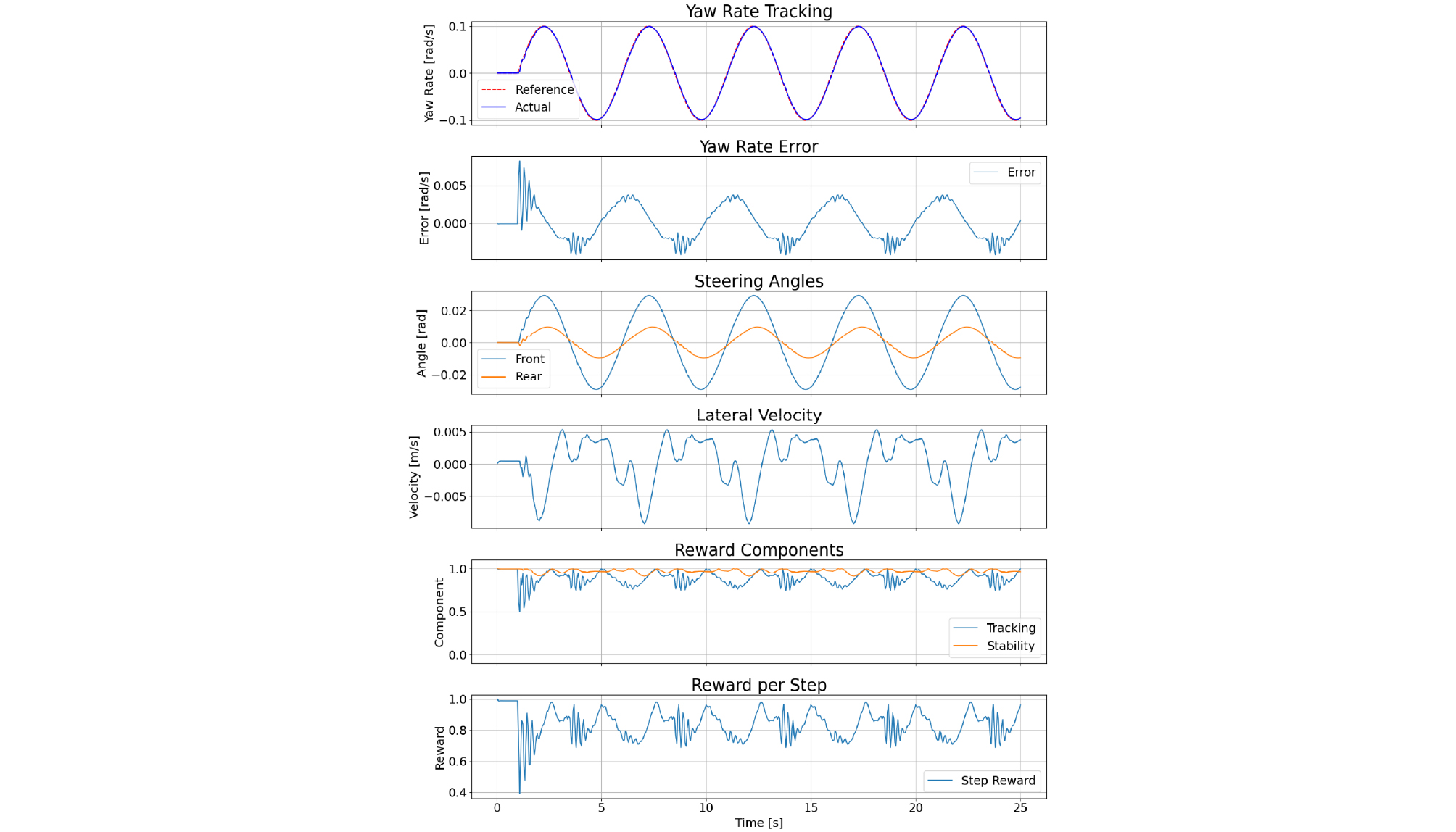
The yaw rate tracking errors for each speed condition are summarized in Table 8.
Table 8.
Yaw rate tracking performance evaluation results
| velocity [m/s] | 10 | 20 |
| Yaw rate error [rad/s] | 0.0028 | 0.0023 |
The experimental results confirm that for both 10 m/s and 20 m/s constant speed conditions, the yaw rate tracking error was maintained near zero. Furthermore, the reward was observed to converge stably, indicating improvements in both tracking performance and vehicle stability.
4.2.2. Case 2: Path Tracking
The path tracking performance of the agent at a constant speed of 20 m/s is illustrated in Fig. 4 and Fig. 5.
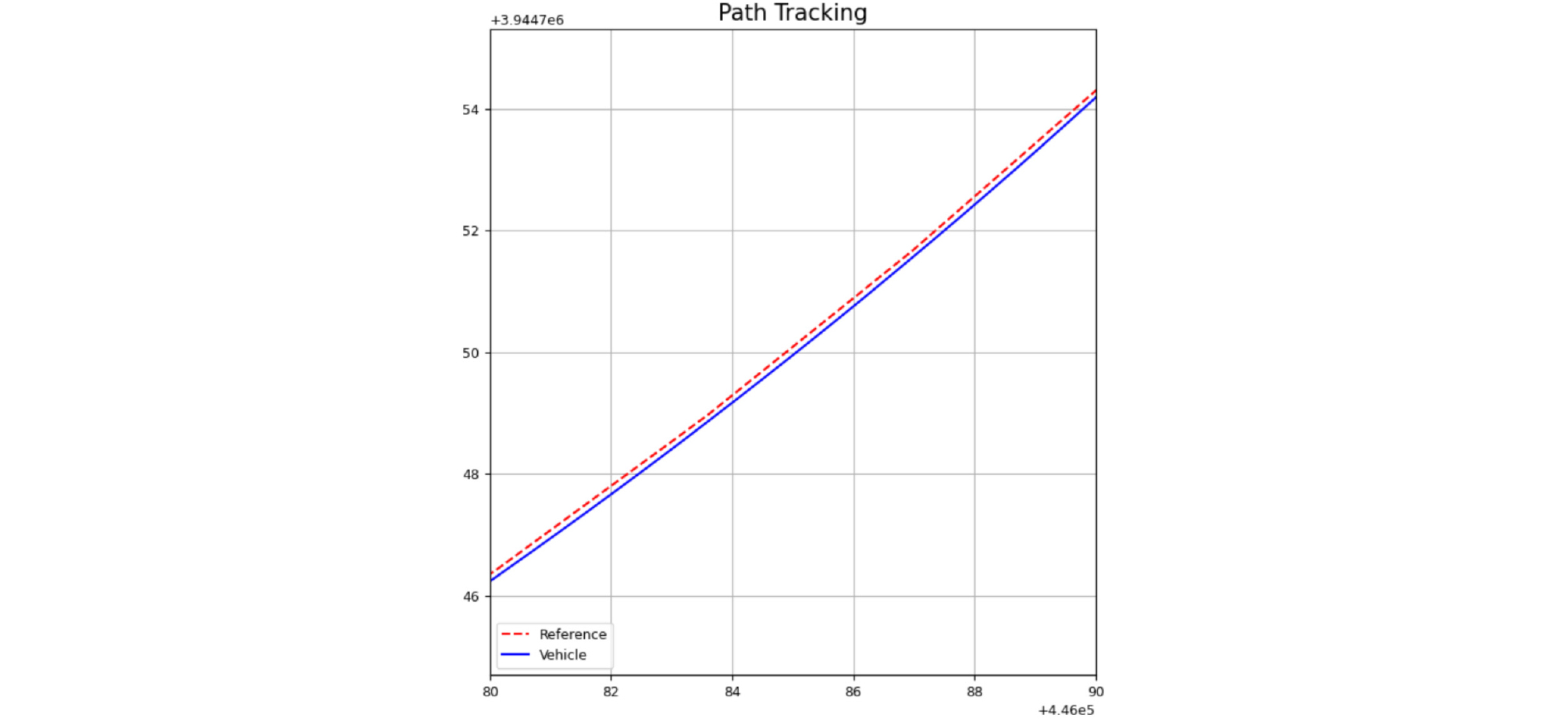
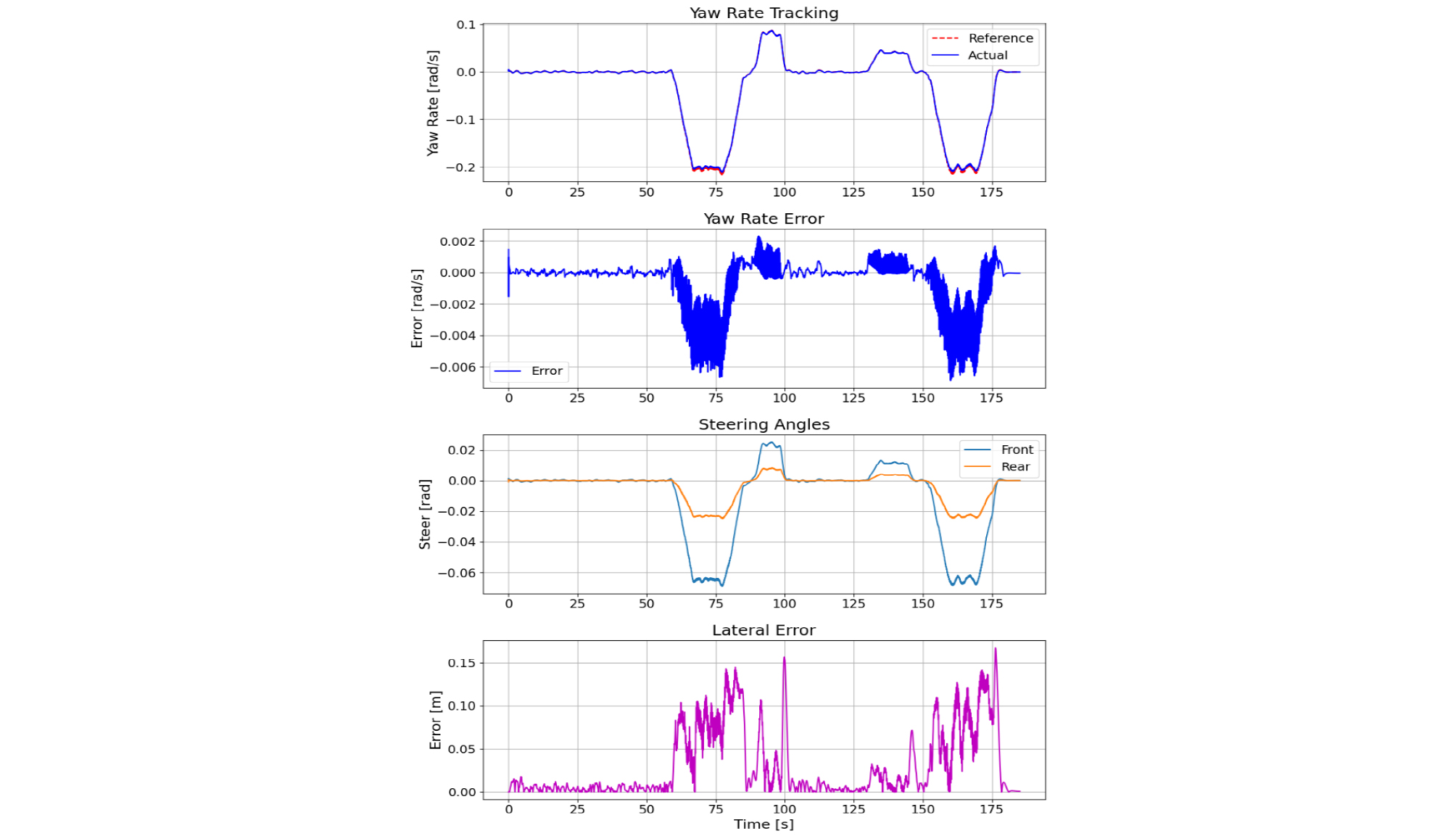
The path tracking performance metrics at a constant speed of 20 m/s are presented in Table 9.
Table 9.
Path tracking performance evaluation results
| velocity [m/s] | 20 |
| Lateral RMSE [m] | 0.0507 |
| Maximum lateral error [m] | 0.1676 |
The experimental results demonstrated that the agent maintained the lateral error near zero, confirming that the target yaw rate was tracked accurately during path tracking.
5. Conclusion
In this study, a reinforcement learning-based path tracking controller was developed to ensure stable tracking performance even under conditions where tire lateral forces exhibit nonlinear behavior relative to slip angles. To this end, a vehicle dynamics model was constructed by applying the brush-based Fiala tire model, which effectively captures tire saturation characteristics with a minimal set of parameters. For the control policy, the Soft Actor-Critic (SAC) algorithm was employed to simultaneously secure exploration and learning stability within a continuous control framework. The steering input was generated based on a front-and-rear steering configuration, a structure designed with future extensibility to E-Corner vehicle platforms—incorporating four-wheel independent steering and driving—in mind. Furthermore, by dividing each environment step into multiple sub-steps, the effects of steering dynamics and nonlinear tire forces on yaw rate and lateral error were simulated more stably and accurately.
Simulation results confirmed that the policy, trained to follow sine-wave target yaw rates, achieved stable tracking across various speed conditions. Moreover, when the trained policy was applied to target yaw rates generated via Pure Pursuit using road coordinates from the KIAPI Proving Ground, stable path tracking was maintained even for path geometries not encountered during the training phase. These results demonstrate that the learned control policy possesses a significant degree of generalization and robustness across diverse path conditions, rather than being limited to specific scenarios.
Future work will build upon the front-and-rear steering policy structure established in this study to incorporate the additional degrees of freedom offered by E-Corner vehicles. This expansion aims to achieve even more robust path tracking control under a broader range of complex driving conditions.
