

1. 서 론
차량의 기술적 발전과 함께 주행 데이터의 수집 및 분석 기술이 발달하면서, 데이터를 통한 운전자의 주행 스타일 및 주행 보조기능에 대한 연구가 활발히 진행되고 있다. 특히 딥러닝 기술이 주행 데이터 분석에 적용되면서 더욱 높은 정밀도와 성능 향상의 가능성이 제시되고 있다. 최근에는 몇몇 보험 회사들은 운전자의 주행 습관을 모니터링하는 앱을 제공하며, 안전한 운전을 할 경우 보험료 할인 등의 혜택을 제공하기도 한다. 또한, 운전자 차량 관련 조작, 상태, 행동 등의 데이터들을 수집하여 분석하고, 운전 스타일을 최적화하거나 스타일에 따른 주행 보조 및 성능을 향상하기 위한 구체적인 방법론이 다양하게 제시되고 있다. 대표적으로 자율주행, 운전자 모니터닝, 트래픽 예측 등 다양하게 주행 데이터 분석에 딥러닝이 적용되며 성능 향상 및 발전해 나아가고 있다.(1,2)
본 연구는 주행 패턴 시각화에 용이한 RGB값 추출을 위하여 Latent space를 세자리로 하면서 최대한 정확도를 높이는 것을 목표로 한다. 이를 위하여 운전자가 조작하는 핸들의 조향각과 종가속도, 브레이크에 가해지는 압력, 차륜 속도 데이터를 수집하고, Attention 메커니즘이 적용된 LSTM-AutoEncoder 알고리즘 모델에 적용해 주행 구간별로 클러스터링하여 이를 RGB 값으로 구간별 다양한 색상으로 시각화한다. 이는 앞서 예시로 설명한 T-map의 사례를 발전시키거나, 자율주행에서 안전성을 확보하기 위해 운전자의 목적을 파악하는 첨단 운전자 지원 시스템(ADAS, Advanced driver assistance system)(3) 기능에 추가하여 운전자의 스타일에 맞는 맞춤형 반응 경고와 반응 방식을 제공하는 등의 주행 보조 기능 연구 발전에도 크게 기여할 것으로 기대된다.
2. 관련 연구
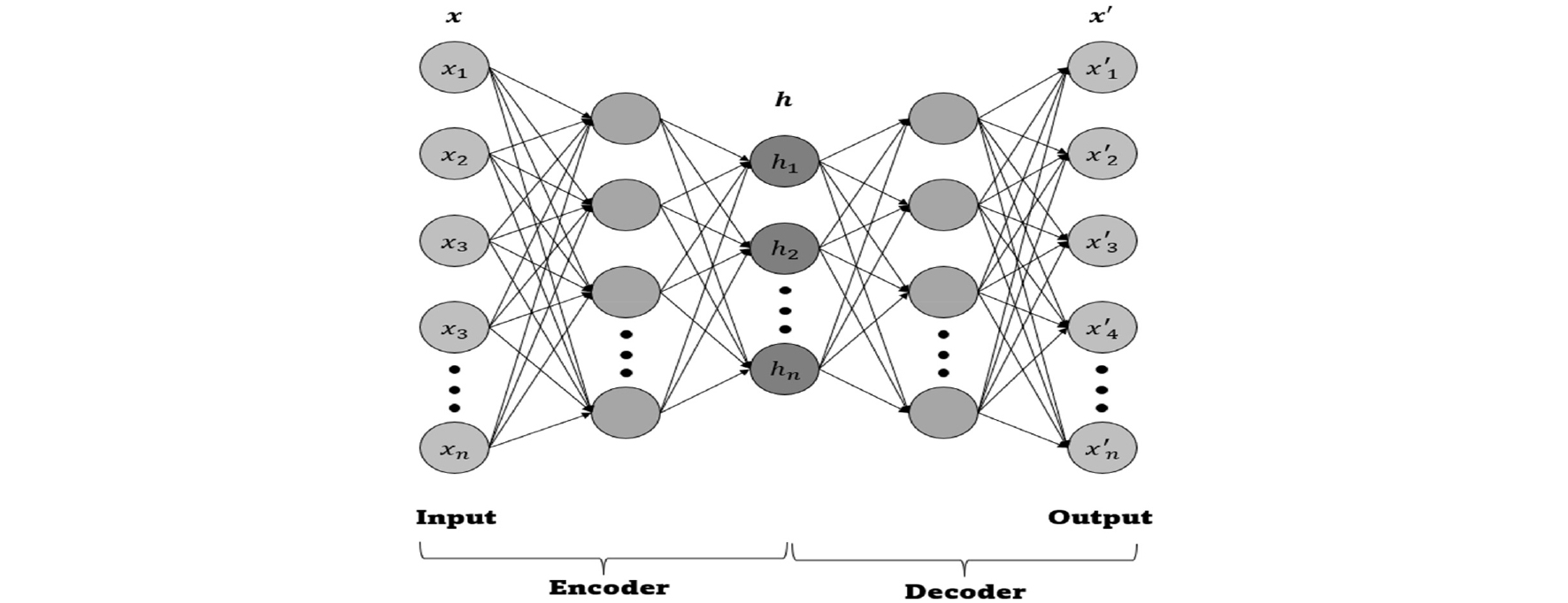
AutoEncoder는 비지도 학습(Unsupervised Learning)에 사용되는 인공신경망 설계 중 하나로, Fig. 1과 같이 데이터의 차원을 줄여 인코딩하는 구성 요소와 압축된 데이터를 다시 복구하는 디코딩 구성 요소로 이루어져 있다. 인코더와 디코더는 대칭적인 구조를 가지며, 복잡한 정보를 간결하게 표현해 데이터를 클러스터링(Clustering)하는 데 유용하며 데이터의 명시적인 라벨링이 필요 없는 이 방식은 다양한 비지도 학습에 적합하다.
여기서 한 단계 발전시킨 것이 스택 AutoEncoder(Stacked AutoEncoder)로, 인코더와 디코더의 여러 계층으로 이루어진 신경망 구조이며 여러 가지 형태가 있다.(4) 특히 LSTM을 접목한 기술은 개별 인코더 계층을 독립적으로 훈련하여 라벨 없는 데이터에서 유용한 특성을 추출하며, 딥러닝 모델의 사전학습(Pre-training)에도 활용된다. 이 기법은 시계열 데이터를 예측하는데 적용되었고, 기존 순환신경망(RNN, Recurrent neural network) 및 WLSTM(Wavelet transformation)에 비해 훨씬 좋은 성능을 보였다.(5) LSTM이 통합된 AutoEncoder는 평균 제곱근 오차(RMSE, Root mean squared error) 관점에서 최상의 결과를 보였으며, 단순 LSTM과 다층 퍼셉트론(MLP, Multi-layer perceptron) 그리고 심층 신뢰 네트워크보다 더 정확한 예측을 제공함으로써, 뛰어난 특징 추출 능력을 갖고 있다.(6)
이와 같은 LSTM-AutoEncoder의 조합은 교통 흐름의 예측에도 적용되었고, 시계열 데이터 분석과 합성곱 신경망(CNN, Convolutional neural network) 및 서포트 벡터 머신(SVM, Support vector machine)과의 비교에서 우수한 성능을 보여주었다.(7)
LSTM-AutoEncoder의 목적은 대규모 시계열 데이터셋에서 복합적인 정보를 수집하고 추출해 내는 것이며,(8) Attention 메커니즘은 모델이 데이터의 특정 부분에 집중할 수 있게 해주는 방법이다. 주로 sequence-to-sequence 모델에서 사용해 기계 번역과 같은 작업에서 사용된다. 시퀀스 데이터가 입력으로 주어질 때, 모든 단어나 토큰이 동일한 중요도를 갖는 것이 아니라 특정 토큰에 가중치를 부여하여 현재 작업에 있어 훨씬 더 중요한 토큰이 무엇인지 알 수 있게 해준다. Attention 메커니즘은 이러한 중요도 즉 가중치를 모델링하여, 모델이 어떤 토큰에 더 집중해야 하는지를 알려주어 학습 성능을 향상 시킨다.(9)
Attention 메커니즘은 차량 관련 시계열 데이터 분석에도 우수한 성능을 보이는데, 주변 차량의 주행 경로를 예측하는 알고리즘에 적용하여 기존 LSTM 모델의 학습 능력보다 우수한 성능을 얻었다.(10)
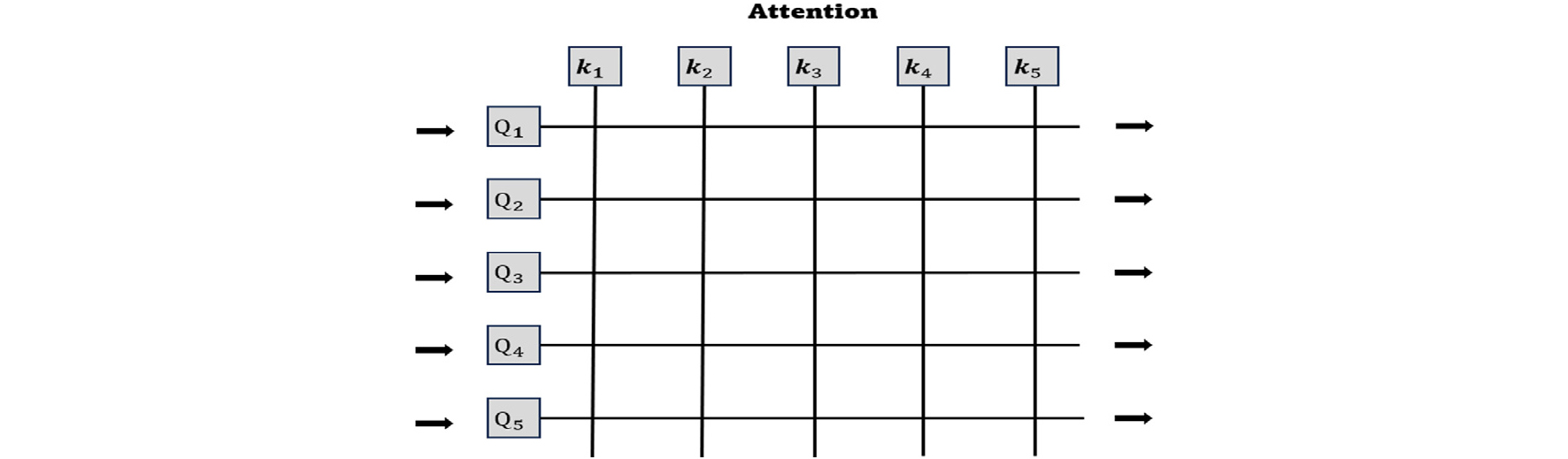
본 연구에서는 이러한 Attention 메커니즘을 적용한 LSTM-AutoeEncoder 모델을 적용시켰다. Fig. 2와 같이 해당 쿼리(Q)와 키(K)의 유사성을 기준으로 각 값에 가중치를 부여한다. 이는 긴 시퀀스에서도 관련 있는 정보를 효과적으로 추출할 수 있다. 이를 통해서 시계열 데이터인 주행 패턴에서 과거의 특정 시점의 데이터, 예를 들어 급제동, 급가속과 같은 특별한 이벤트가 현재의 출력에 큰 영향을 미칠 수 있으므로 이러한 중요한 시점에 더욱 집중하여 정보의 시간적 의존성을 더욱 잘 포착하였다. 주행 중에 발생하는 다양한 상황과 패턴에 있어서 일부 구간은 다른 구간보다 중요한 패턴이나 변동성을 포함할 수 있다. Attention 메커니즘은 이러한 특정 구간에 더 많은 가중치를 부여하여, 변동성 높은 주행 패턴이나 특별한 이벤트를 효과적으로 포착한다.
3. 인공신경망 모델
3.1. 데이터셋
본 연구에서 사용한 데이터셋은 서울대학교 미래 모빌리티 기술센터(FMTC; Future Mobility Technology Center)의 시험주행 트랙에서 실제로 운행하여 수집되었다. Fig. 3은 FMTC에서 데이터 수집에 사용한 주행 코스를 나타낸다. 데이터 수집에 사용한 주행 코스는 Fig. 3과 같이 몇 가지 주요한 코스들을 포함하고 있다.
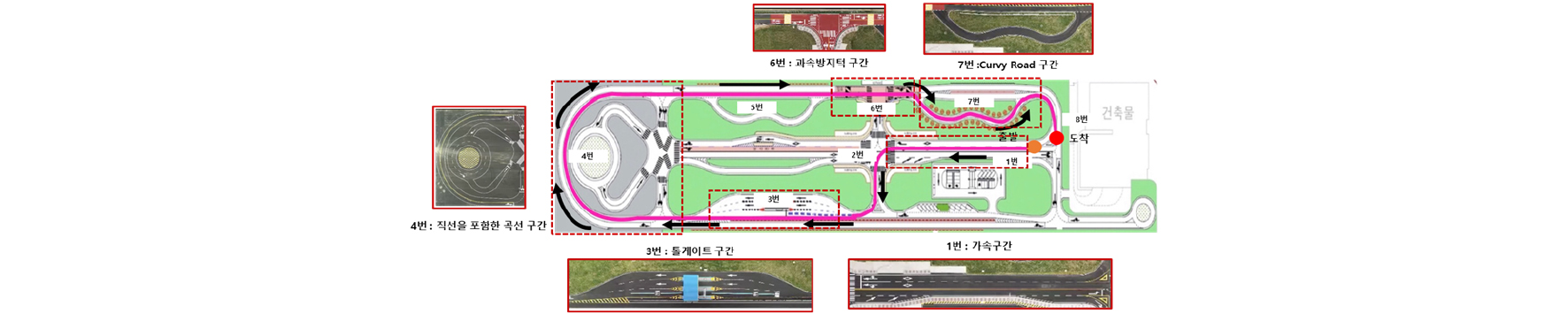
주행 데이터는 100 Hz로 수집되었고, 약 350,000개의 데이터로 구성된다. 수집된 데이터들 중 조향각(deg), 종가속도(m/s2), 브레이크 압력(bar)과 차륜 속도(km/h)의 4개 속성을 학습에 사용하였으며, 윈도우 사이즈를 10으로 사용하여 10 Hz(0.1초)의 데이터가 들어갈 수 있도록 데이터세트를 구성하였다.
3.2. 모델 구조
본 연구에서 사용한 LSTM-AutoEncoder와 Attention을 포함한 모델 구조는 Fig. 4와 같다. 인코더 부분에서는 LSTM 계층을 통해 입력 데이터를 순차적으로 처리한다. LSTM 계층은 128개의 유닛을 가지고 sigmoid를 활성화 함수로 사용한다.
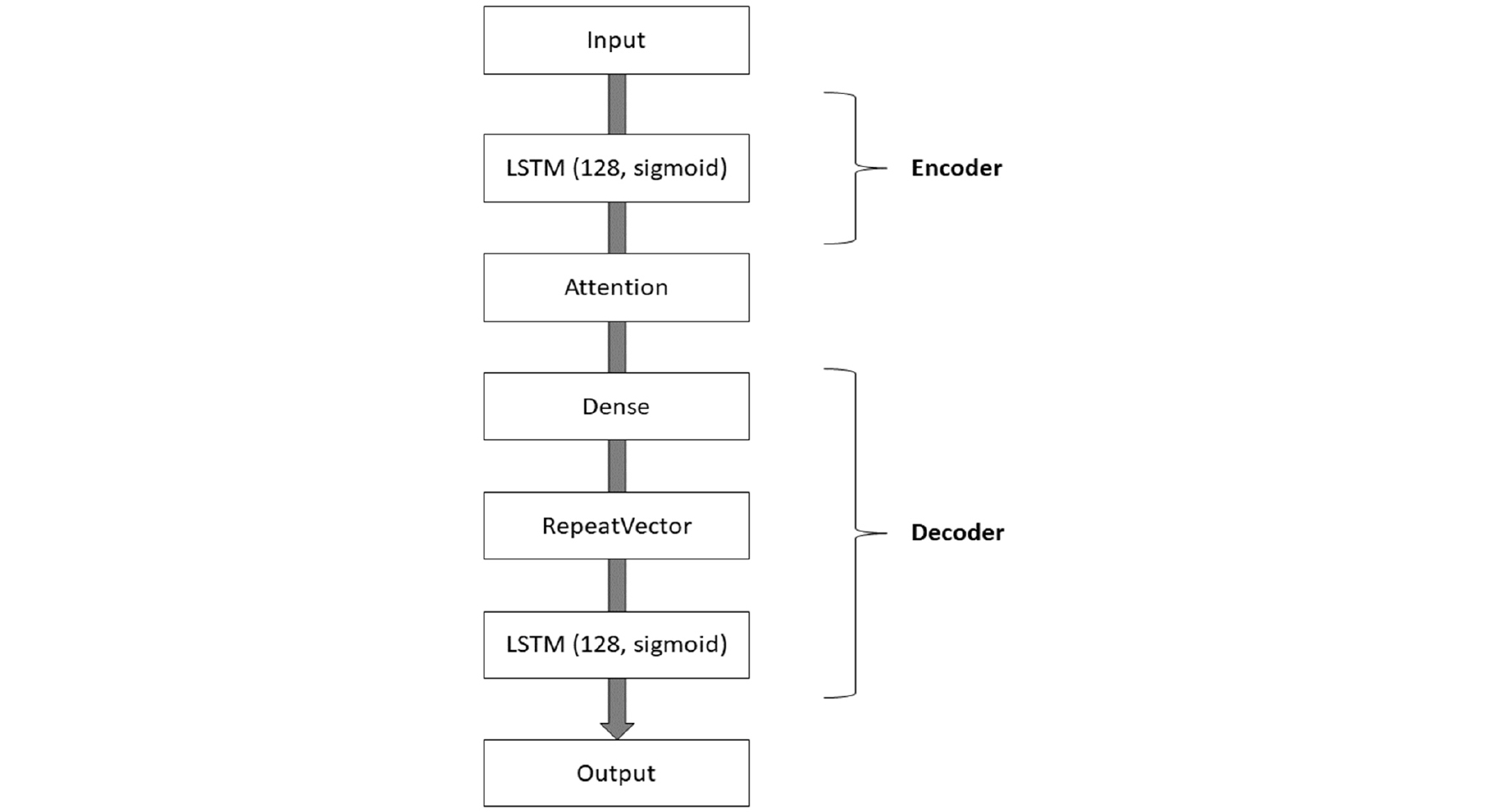
이렇게 인코딩된 정보 위에 Attention 메커니즘이 추가된다. Attention 메커니즘은 인코딩 과정에서의 각 시퀀스 위치에 대한 중요성을 계산하여, 특정 정보에 더 큰 가중치를 주는 역할을 한다. 이를 통해 모델은 입력 데이터 내의 중요한 특징에 집중할 수 있게 된다.
Attention 계층 이후 3개의 유닛을 가진 전결합(Dense) 계층을 거쳐 데이터가 압축되고, RepeatVector를 통해 디코더에 맞는 시퀀스 길이로 변환된다. 디코더 부분에서는 압축된 데이터를 다시 원래의 형태로 복원하기 위해 128개의 유닛을 갖는 LSTM 계층을 사용한다.
본 모델은 입력 데이터의 주요 특징을 Attention 메커니즘을 통해 강조하고, 이를 기반으로 원본 데이터 형태로 복원하는 역할을 수행한다. Attention의 도입은 모델이 중요한 정보에 더욱 집중하며 성능을 향상시킨다.
4. 실험 결과
4.1. 하이퍼 파라미터
Table 1은 Attention이 적용된 LSM-AutoEncoder 모델을 구현한 학습 환경을 나타낸다. 해당 환경에서 학습을 진행하였으며, Table 2는 본 연구에서 사용한 학습 모델의 하이퍼 파라미터값을 나타낸다. 신경망 모델에서 손실함수는 예측값과 실제 값 사이의 차이를 측정한다.
Table 1.
Setting the algorithm model operating environment
| Name | Version |
| Python | 3.7.15 |
| Tensorflow-gpu | 2.6.0 |
| Scipy | 1.7.3 |
| Scikit-learn | 0.12.2 |
| Seaborn | 1.0.2 |
| Pandas | 1.3.5 |
| numpy | 1.19.5 |
이번 연구에서는 다양한 손실함수 중에서 평균 제곱 오차(MSE, Mean squared error)를 선택하여 사용하였다. MSE는 예측된 값과 실제 값의 차이 제곱의 평균으로 정의되며, 식 (1)과 같이 표현된다. 이 MSE는 실제값에 대한 정확도 불일치 및 오류 정확도를 포함하여 연산이 이루어진다. 이러한 특성으로 인해 MSE는 최적화 과정에서 최적값으로 수렴하는 데 효과적이기 때문에 이 연구에서 이를 손실함수로 선정하였다.
손실함수 MSE를 사용하여 나온 측정 결과 오차 값은 0.1미만의 결과를 얻었다.
4.2. 학습 결과 및 시각화 결과
Table 3은 LSTM 계층 수를 1개에서 4개까지 각각 5회 훈련을 진행하여 재구성 오차(MSE) 평균을 계산한 것이다. LSTM Layer 2, 3인 경우는 약 31 정도의 평균값을 보이며, Layer 4인 경우 약 43으로 재구성 오차가 확실하게 높아지는 것을 확인할 수 있다. 반면, Layer 1개인 경우 26 정도의 평균값으로 다른 3개와 가장 낮은 재구성 오류를 확인할 수 있었다. 따라서 LSTM Layer 1개를 적용하여 실험을 진행하였다.
Table 3.
Comparison of the average results from five experiments for each number of layers
| Layer | Average MSE value from five runs |
| 1 | 26.30536 |
| 2 | 31.99667 |
| 3 | 31.36912 |
| 4 | 43.62721 |
Fig. 5는 모델 학습에 사용된 데이터 feature 값의 인코더 출력값과 디코더의 출력값을 같은 값에 올려둔 그래프이다. 그래프의 x축은 데이터 수를, y축은 각 데이터의 값을 나타낸다. 이는 원본과 예측값이 어느 정도 일치하는지를 시각화하기 위해 나타낸 것이다.
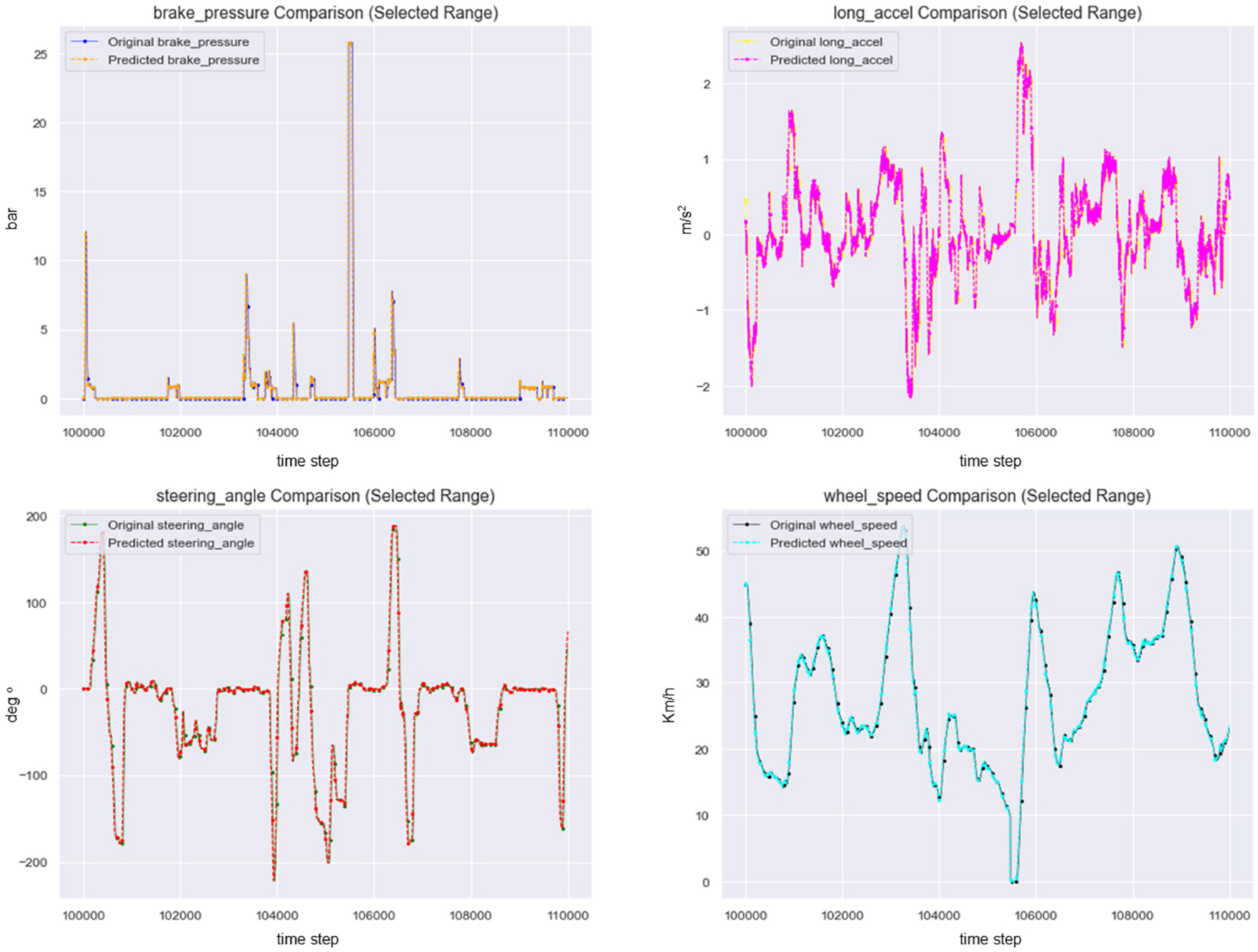
Fig. 6에서 기존의 Attention 없이 LSTM만 사용한 AutoEncoder의 성능은 95%이며, Attention이 적용된 LSTM-AutoEncoder 모델의 재구성률은 96% 이상의 값을 보이며 약 1% 정도 향상된 결과이다. 이는 인코더의 출력값과 디코더의 출력값이 거의 일치한 결과를 나타낸다.
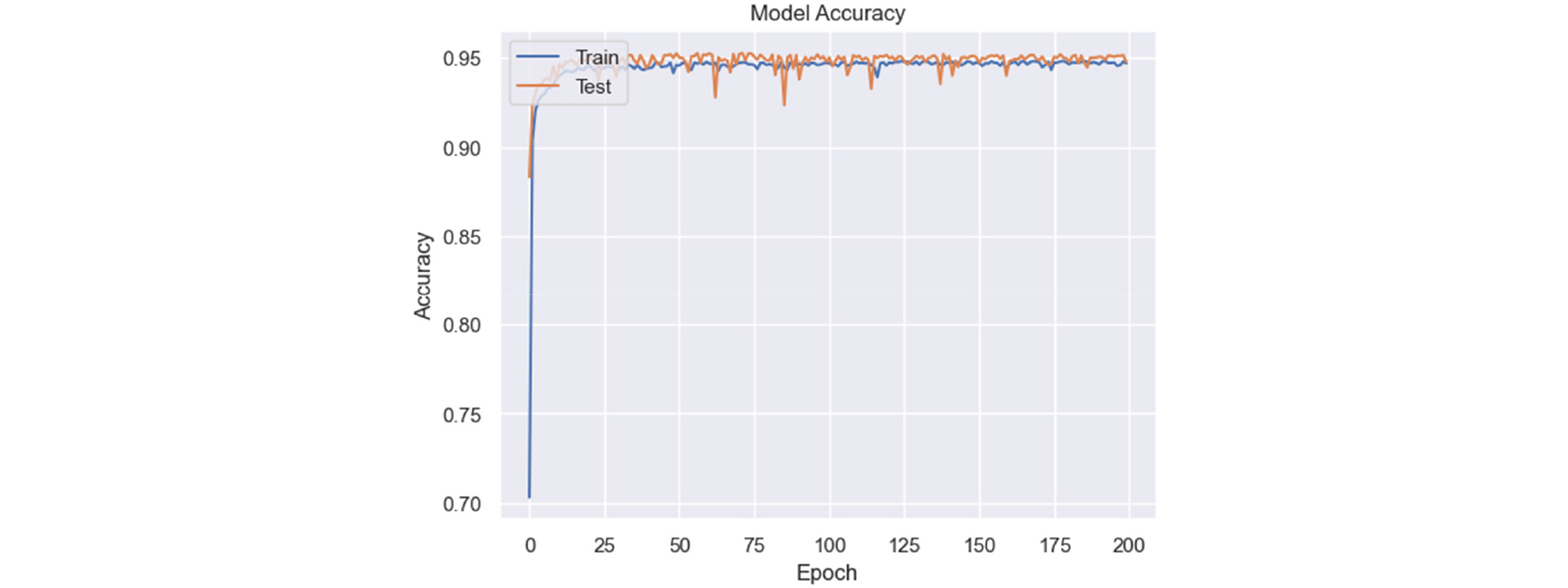
Fig. 7은 RGB 값을 사용해 구분하여 트랙 구간을 시각화한 자료이다. 인코딩된 출력값의 스케일링을 진행 후, 클러스터링을 통해 총 9가지의 특징별로 구분한다. 그룹별로 평균 RGB 값을 계산하여 대체한 뒤, 구분하기 편리하도록 시각화한 것을 확인할 수 있으며, Table 4에서 색상마다 구간의 특징을 정리하였다.
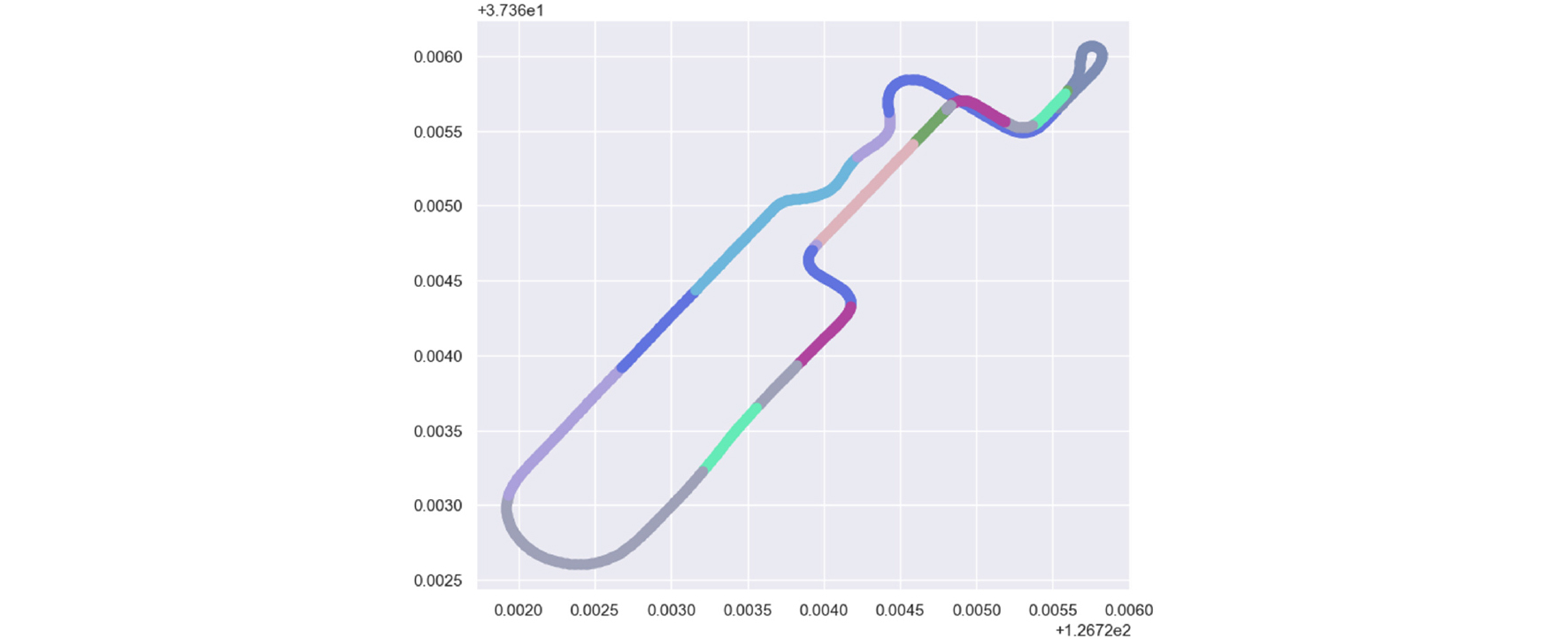
Table 4.
Colors clustered by section
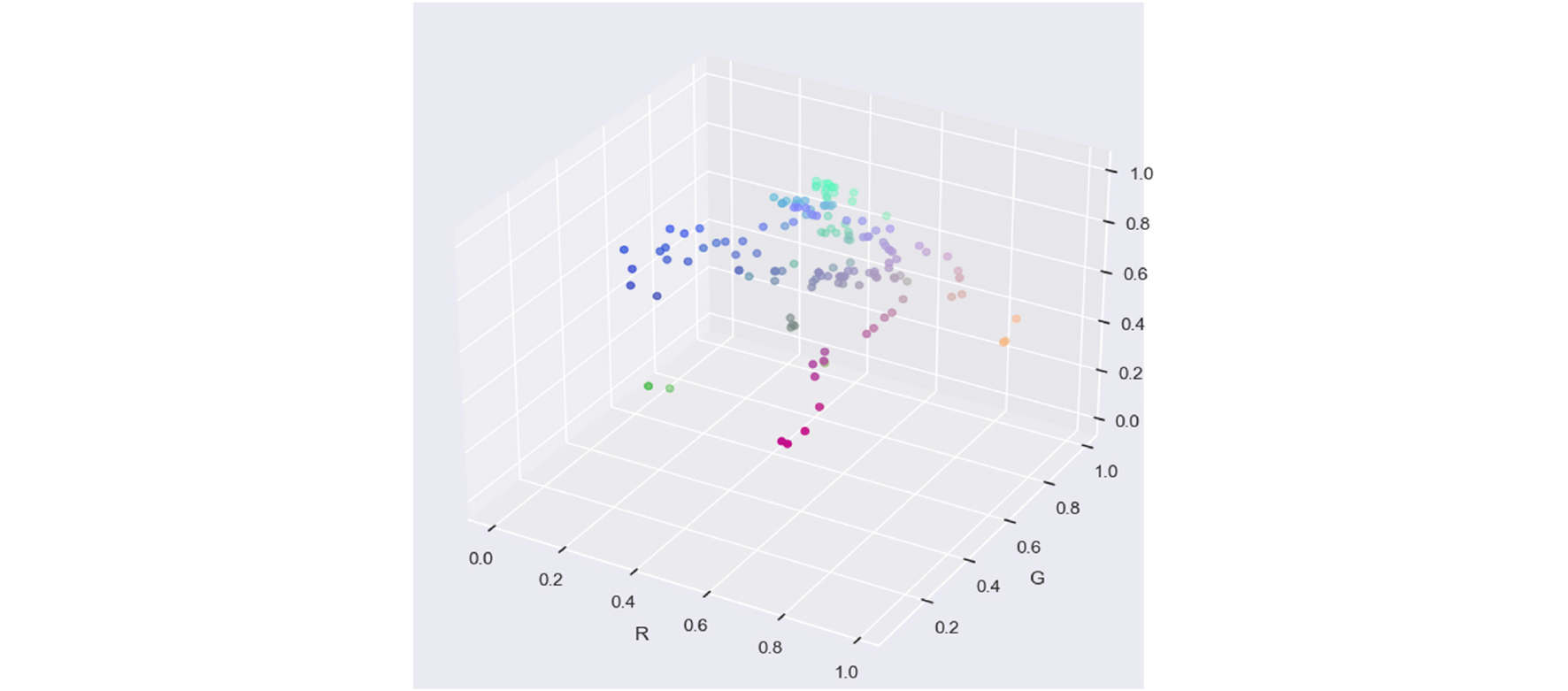
Fig. 8은 클러스터링을 통해 RGB 값을 계산하여 평균 RGB 값을 계산하기 전의 색상 분포 정도를 나타낸다.
5. 결 론
본 연구에서는 Attention 메커니즘이 적용된 LSTM-AutoEncoder 모델을 이용하여 차량 주행 데이터를 특징마다 클러스터링하여 시각화하고 비교하는 알고리즘을 개발하였다.
개발된 알고리즘은 차량 주행 간의 운전자가 조작하는 데이터인 조향각, 종가속도, 브레이크의 압력과 차륜 속도들을 학습하여 이를 클러스터링하고 RGB 값으로 표현한다. 이때 RGB 값을 통해 특정 구간들을 색으로 시각화할 수 있게 된다. 인코더 출력값과 디코더 출력값을 비교한 결과인 재구성률이 96%에 도달함을 확인하였다. 이를 통해 본 연구에서 개발된 알고리즘을 사용하여 운전자의 주행 패턴을 분석함으로써, 운전자 개개인의 주행 스타일에 맞는 주행 보조 기능과 운전 능력 향상에 활용할 수 있다. 또한 실시간으로 받아오는 데이터를 통해 최근 화제가 되는 급발진 의심 사고 시 차량 또는 운전자의 과실을 확인하기 위해, 높은 차륜 속도일 때의 데이터를 받아 속도 증감 시의 종가속도와 브레이크 압력 데이터를 확인하여 신속하게 판별하는 데 도움을 줄 수 있을 것으로 보인다.
하지만 본 연구의 Attention 메커니즘을 적용한 LSTM-AutoEncoer 모델을 사용하여 차량 주행 패턴을 클러스터링하고 시각화하는 데 몇 가지 한계점이 존재한다. 첫 번째는 수집된 데이터의 부족이다. 차량 주행 데이터는 다양한 조건에서 수집될 필요가 있지만, 본 연구에서 사용된 데이터는 특정 도로에서만 수집된 것으로, 모든 도로 환경이나 운전 상황을 포함하지는 못한다. 두 번째는 특정 운전자의 주행 데이터를 사용하였기 때문에 운전자의 연령, 성별, 그리고 경력 등과 같은 다양한 변수를 고려한 데이터를 사용하지 못했다는 한계점이 존재한다. 마지막으로 LSTM-AutoEncoder 모델의 복잡성으로 인해서 실시간 적용에서의 계산 비용이 높다는 점이다. 차량 주행 데이터는 실시간으로 처리되어야 하는 경우가 많기 때문에, 더욱 경량화된 모델 혹은 계산 효율성이 높은 알고리즘을 탐색이 필요하다고 판단된다.
향후에는 재구성 오차를 감소시키는 방안으로 Transformer 기법을 적용한 모델을 연구할 예정이다. Transformer는 Self-Attention 메커니즘을 통해 시계열 데이터의 장기 의존성을 효과적으로 학습할 수 있으며, 병렬 처리로 인해 계산 효율성이 높아 실시간 주행 데이터 분석에 유리하다. 또한, 위치 인코딩을 통해 시계열 데이터의 순차적 특성을 반영하여 더욱 정교한 주행 패턴 분석이 가능할 것으로 기대된다.
